








 Microsoft Fabric
Microsoft FabricWhy LLMs, vector databases, and knowledge graphs can’t fix what semantic modeling was built to solve.
The AI promise has hit a wall
Your AI-powered analytics is wrong so often that even the right answers are suspect. Was the AI promise a lie? Or is your organization just approaching it incorrectly?
Asking the right questions without the right context still produces the wrong response. That’s a data foundation problem dressed up as an AI problem. The pipeline isn’t broken. The query returned what you asked for. But the answer is still wrong because nobody told the system what your business actually means.
The 2026 CDO Insights study from Informatica and Wakefield (600 data leaders, $500M+ companies) measures the cost. 50% of agentic AI adopters now name data quality as their top production blocker, ahead of security, tooling, and safety guardrails. 57% call it the top barrier to pilots hitting prod, unchanged year over year. 76% admit governance hasn’t kept pace with how their teams already use AI, and 61% rank it above budget, headcount, and executive buy-in as the single factor most likely to determine whether GenAI ever ships.
These aren’t problems you solve by buying another vector database or fine-tuning another model. They share a root cause older than ChatGPT: your AI stack has no shared definition of what your data actually means. Semantic modeling is the layer that defines it, and in most enterprises, nobody owns it.
Why your LLM, vector DB, and knowledge graph can’t fix this
The natural reflex, when an AI initiative stalls, is to throw more AI at it. A bigger model. A better embedding. A graph database. A second vector store. All great tools, but none of them produce meaning. They redistribute it.
LLMs generate plausible answers from patterns in text. They have no privileged knowledge of your business. When your model sees net_amount, it doesn’t know whether your company nets out returns, intercompany transfers, or FX adjustments. It will produce a confident answer regardless, and which “regardless” you get depends on the prompt, the day, and the temperature setting.
Vector databases retrieve content by similarity. Similar is not the same as correct, especially when it comes to metrics. A vector search will surface the document that talks the most about ARR (e.g., your CFO’s deck, your quarterly board memo, your sales playbook), but it has no way of knowing which of those three contains the authoritative definition. It finds the closest neighbor in semantic space, and “closest” is a vector-math accident.
Knowledge graphs are closer to the right idea. They encode relationships, which is half the work of a semantic layer. But a graph is only as useful as the business meaning somebody bothered to put in it. The graph doesn’t know that Customer → has_account → Account is the relationship Sales cares about and Customer → has_subscription → Subscription is the one Finance cares about unless you told it. And if you told it, congratulations: you have a relational model that will underpin your semantic model.
These tools are all downstream of the semantic gap. They can’t synthesize meaning that isn’t already encoded somewhere upstream. And that gap shows up in three predictable ways:
- Tribal knowledge. Column names like net_amount don’t tell AI whether to include returns, apply FX, or exclude intercompany. The knowledge exists, but it lives in the head of an analyst who left in 2023.
- Authoritative sources. Without a semantic model, AI lacks instructions that say “use this fact table for revenue, not that one” and “use this column to join to customer master data, located here.” So AI has guesses.
- DDL lacks nuance. Schemas have no concept of synonyms, filters, or calculations. When “active customer” means three different things to three teams, AI is no better than chance. If the “North America” grouping is defined upstream as a Dashboard filter, AI is blind to its existence.
Without a semantic model, every dollar you spend on an LLM, RAG pipeline, or graph database doesn’t reduce ambiguity. It simply compounds across more surfaces.
What a semantic model actually is
A semantic model is the layer between your physical schema and your humans. It does three things:
- Translates structure into business language. cust_id_pk becomes “Customer.” gl_acct_405200_ytd becomes “Operating Expense.” Every table and column carries a name that a human would actually use.
- Encodes relationships and logic. Which fact table is authoritative for revenue? How does “Active Customer” filter against the subscription table? What does “this quarter” mean when the fiscal year ends in March? These aren’t queries, they’re definitions.
- Acts as a single source of truth. Same metric, same definition, same answer, across every department, dashboard, and AI agent that touches the data.
That last one is the one that matters for AI. Not because AI needs a friendly UI on SQL, but because every consumer of your data (e.g., every dashboard, every analyst, every Cortex agent) references the same authoritative answer to what does revenue mean here?
Think of the semantic layer as the third step in a four-step journey, the journey most enterprises stop after step two.
- Step 1: Star schema. Silos eliminated; data modeled into facts and dimensions. Most large companies are here.
- Step 2: Data products. Curated, governed assets with owners and SLAs. Many companies are here.
- Step 3: Semantic model. Definitions of what those data products mean, with explicit relationships and business logic. Far fewer companies are here.
- Step 4: End-user AI solutions. Cortex agents, conversational interfaces, and autonomous workflows, powered by step 3.
Skipping step 3 is the most common mistake in enterprise AI today. Companies invest in AI solutions, thinking that a star schema or a data contract is enough. It isn’t. The data product tells AI where to look. The semantic model tells AI what it’s looking at.
There’s another way to see what makes the semantic layer distinct. Most of its building blocks (e.g., tables, columns, primary keys, foreign keys, descriptions, tags) overlap with the physical model. A few, like dimensions, facts, and metrics, overlap partially: the column exists, but the meaning (this is a measure, this is a grain) is semantic. And then there are artifacts that exist only in the semantic layer:
- Synonyms — alternate names the business actually uses. “Client” maps to “Customer.” “GMV” maps to “Gross Merchandise Value.“
- Sample values / enums — the list of valid options for a dimension, so AI doesn’t hallucinate that “Status = Yes” is a thing.
- Filters — named conditions like “Active Customer” or “Last Quarter” that AI applies without guessing.
- Verified queries — known-good question/SQL pairs that anchor accuracy and double as in-context examples.
These are exactly the artifacts AI engineers keep trying to recreate in ad hoc prompts, few-shot examples, and evals. They belong in the model, not in a markdown file someone pastes into their RAG chain.
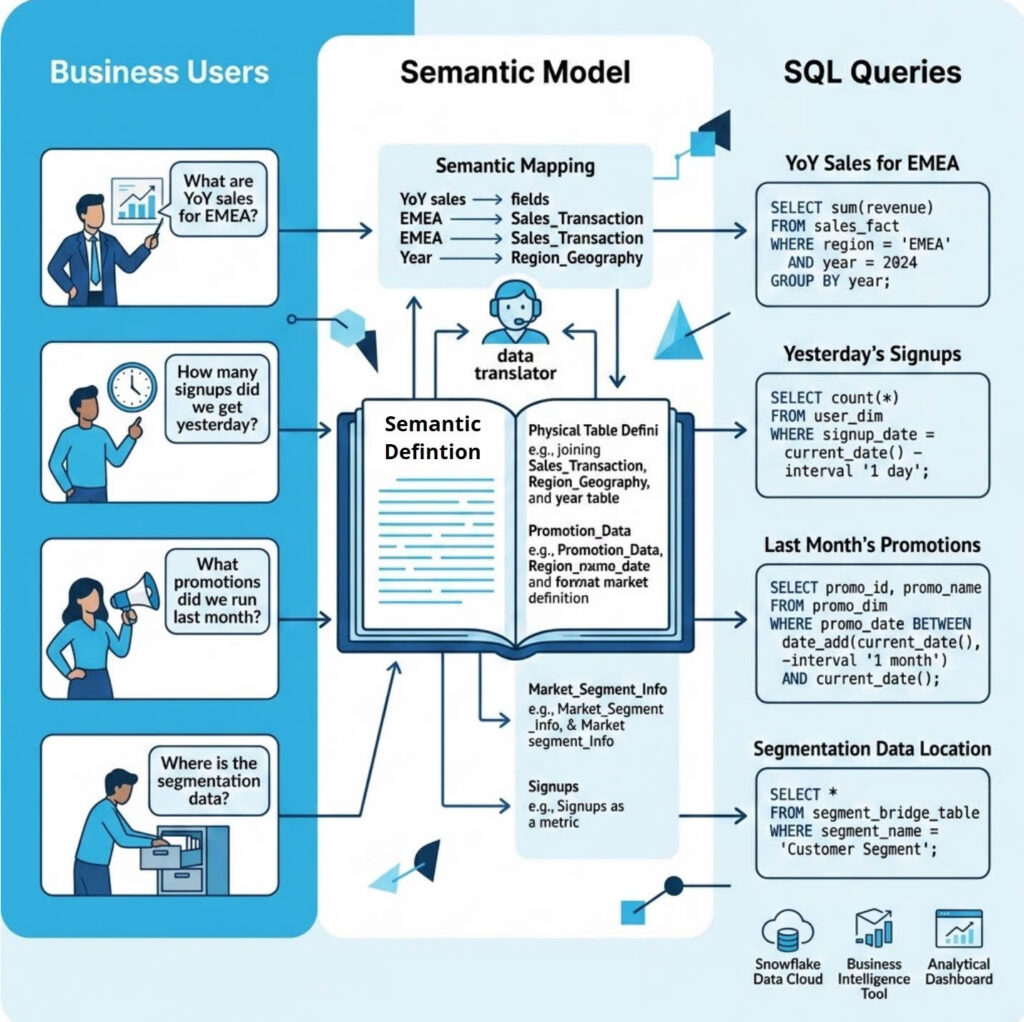
Where it fits in agentic architecture
Snowflake recommends breaking down AI agents in layers: Ground → Reason → Act. Ground is the context that provides the data and meaning the agent operates over. Reason is the decision intelligence (i.e., planning, retrieval, evaluation). Act is the interface (e.g., conversational, autonomous, human-in-the-loop, etc).
The Context layer has four pillars: all your data accessible (no silos), workflows and procedures, system connectors, and semantic understanding. The first three are the kind of thing enterprises buy: cloud migration, data integration, and automation projects. Semantic understanding has to be built, and it’s what determines whether the other three actually work.
Without it, an agent reasoning over the right data still produces the wrong answer. Two agents querying the same warehouse return different totals. A “reasoning loop” reasons over ambiguity and lands in the uncanny valley of plausibility. But none of that is visible to the user because the answer is wrong in a way that can’t be debugged from the prompt.
This is the part for a CDO to internalize: every autonomous decision your organization makes over the next three years runs on top of this layer. A refund issued in the wrong currency. A customer flagged as churned when they aren’t. A forecast that includes intercompany. The cost of those mistakes scales with how much you’ve automated on top of a foundation nobody owns.
Ground first. Reason after.
Your job: govern the semantic layer
If you’re a CDO and you’ve followed this far, the implicit question is who owns this? The answer is you, or somebody who reports to you. There isn’t a third option. Semantic models are the layer where engineering, BI, and business definitions converge. Either semantic models are owned with intention, or they become the next shadow IT.
Here are five practices that can help rein in the challenge:
1. Govern. Define ownership for every metric and dimension. Establish a review process. Treat it the way you treat any other strategic asset. The alternative is what most companies have today: definitions that drift across BI tools, query logs, and Confluence pages—none of them is authoritative, yet all get referenced in one manifestation or another in your analytics.
2. Shift left. Push semantic definitions down to where the data lives, not the BI tools. A definition that exists only in a Tableau workbook supports only one report. A definition that lives in the semantic layer governs every consumer downstream, including the ones you’ll build tomorrow.
3. Reuse. Define once, reuse everywhere. If a metric is defined in a semantic model but no one hears about it, does it really make a sound? Semantic model governance isn’t just about intrinsic accuracy. It’s also about looking outward to ensure downstream sources point to the model rather than redefine those same metrics.
4. Disambiguate. Sales and Finance both have a valid definition of “customer.” Marketing has a third. Knowing when to reconcile and when to split is the work. There’s no algorithm for it. (More on this later.)
5. Validate. Test definitions with business stakeholders the same way you’d test any other deliverable. A semantic model that hasn’t been validated by the people whose questions it answers is no better than a guess.
This is the part of the conversation where “governance” usually triggers the executive flinch. It shouldn’t. Governance, applied here, is what actually lets you ship AI faster. Companies that govern their semantic layer deploy AI faster and with more executive trust than those that skip it. Companies that skip it are the ones still running 18-month “exploration” phases on what should be production workloads.
Governance isn’t the blocker. It’s the prerequisite.
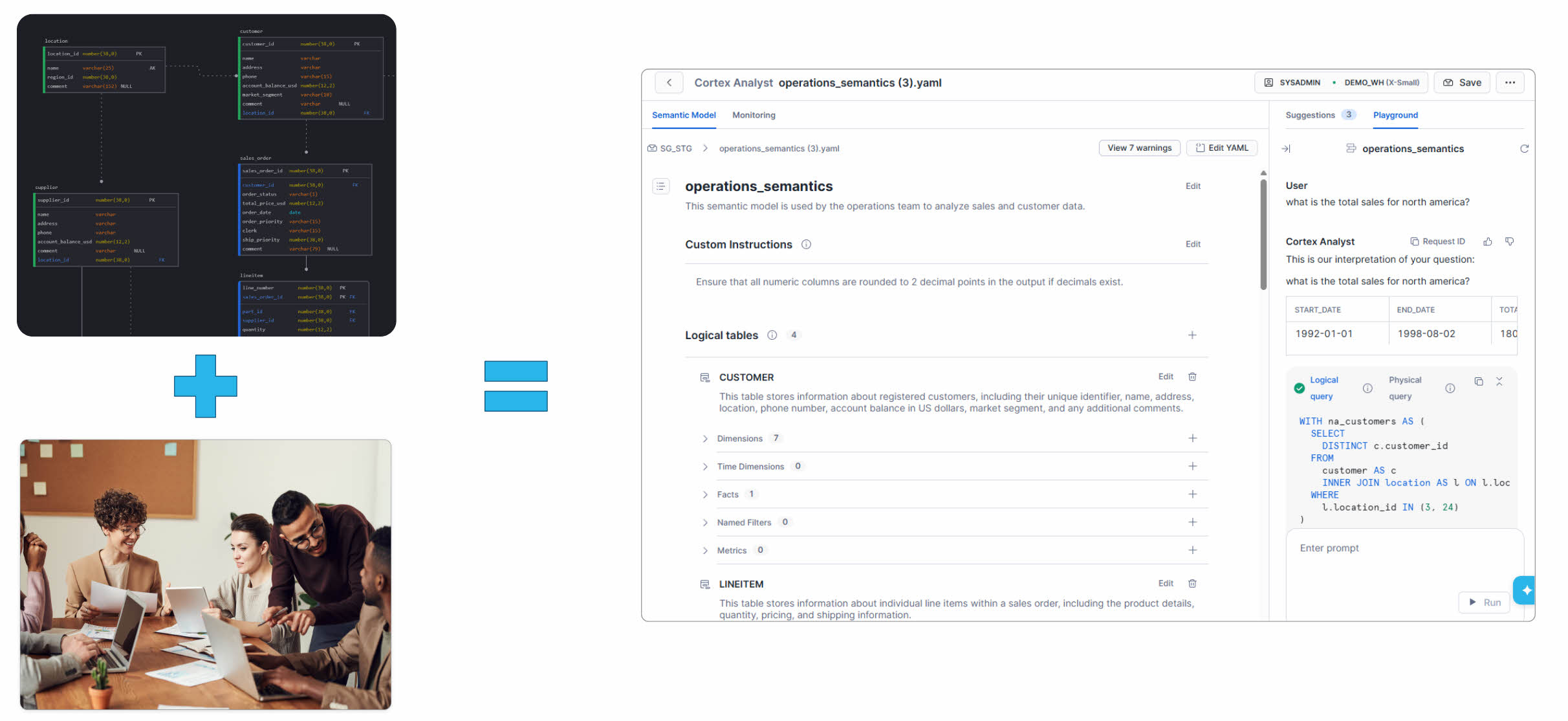
Where semantic models actually get built and governed
The hard part of governing semantic models is operational. Defining ownership is one thing. Implementing a system where 200 analysts and a dozen agents reference the same authoritative metric is another.
The challenge isn’t generating a semantic model—Snowflake’s Semantic Model autopilot can help do that-It’s keeping one accurate over time. A semantic model is a living artifact. Schemas change. Business definitions evolve. New teams onboard, each with their own opinions about what “active customer” means. A model generated six months ago doesn’t survive contact with any of that.
This is where SqlDBM plugs and keeps your semantic models grounded. It does so in four important ways:
- Foundation. A governed physical model is what makes semantic modeling tractable. If your warehouse schema is undocumented, no semantic layer above it will survive contact with reality.
- Update propagation. Schema changes flow into the semantic model automatically. Semantic defaults also propogate across models, keeping them in sync.
- Collaboration. Real-time, multi-user editing with shared visibility. The single biggest fix for semantic sprawl is making it impossible for two teams to silently redefine the same metric.
- Drift highlighting. When the semantic model diverges from the physical model or the established semantic defaults, SqlDBM highlights it. Any variations in definitions, synonyms, or expressions are brought to the team’s attention to ensure intentionality and prevent unintentional drift—the silent killer of trust in AI outputs.
As with all database objects, SqlDBM automated the the entire round trip with Snowflake Semantic Views from reverse engineering, updates, and forward engineering out to Cortex, keeping the database, the model, and the AI consumers in sync. Same definitions, same governance, same answers across the stack.
If your semantic layer doesn’t live where your data engineers, modelers, and BI leads already work and collaborate, it won’t stay current. And if it doesn’t stay current, you don’t have a semantic layer.
Five gidelines for building a semantic model
My role at SqlDBM gives me a privileged view into the practices that leading enterprise team employ to turn semantic models into strategic assets. These practices separate the semantic-modeling efforts that ship from the ones that stall:
Work top-down. Start from the questions the business actually ask. Attempting to blanket the entire data warehouse in semantics is boiling the ocean. Instead, start with the data sources that matter most and disambiguate the biggest sources of contention.
Engage SMEs early. A semantic model is a negotiated artifact, not a derived one. Failing to engage the true owners of your business metrics and concepts will result in a return to the drawing board and wasted UAT cycles.
Be Jerry Springer. When two teams disagree on a definition, your job isn’t to pick a winner. It’s to surface the conflict, get the stakeholders in the same room, and broker a resolution, or, where appropriate, split into two clearly-named variants (revenue_finance, revenue_sales). Most modelers want to hide from conflict but this is where the real value lies.
Don’t neglect verified queries. Data teams sometimes get so hung up on an individual column that they forget that entire queries can be stored as part of a semantic model—and there’s no limit to how many you define. Entire analyses can be encapsulated here and paired with a human readable question like “year-over-year cancelations for high-gross orders” which pack many business terms, filters, and concepts into a pre-approved SQL statement.
Enforce upstream. Make the semantic layer the path of least resistance through governance, tooling, and curated data access layers. A semantic layer with an off-ramp is a semantic layer with a half-life.
Conclusion
The single biggest takeaway is that AI accuracy fundamentally starts with the data model. Technologies like Cortex, agents, and MCP servers can not generate accurate answers without proper guidance. The semantic model plays that crucial role. The irony is that many enterprises will spend the next two years recovering from the mistake of prioritizing foundation models over establishing solid modeling foundations. This is like meeting the world’s greatest data engineer at a dinner party and asking them “how many active customers do I have?”
Semantic models serve as the essential bridge that translates technical structures into governed business logic for AI consumption. Without such a bridge, investments in AI often lead to increased ambiguity rather than valuable insights.
Given the high stakes (and costs) of AI data strategy, the investment in the creation, governance, and scalability semantic models is the critical factor you simply cannot afford to ignore. These models are not merely supportive but are essential as a strategic foundation of your data strategy.
Therefore, if you’re considering approval for an agentic AI initiative this quarter, it’s vital to assess your semantic foundation first. Every dollar invested above this layer builds upon what exists underneath, so ensure that there is a solid structure in place.